
Mazāk ir Vairāk: Kā Mazāk Dokumentu Iegūšana Var Uzlabot AI Atbildes
Mazāk var nozīmēt vairāk: kā dokumentu atlase ietekmē AI atbildes
Retrieval-Augmented Generation (RAG) ir pieeja, kas apvieno valodu modeli ar ārēju zināšanu avotu. Vienkārši sakot, AI vispirms meklē atbilstošus dokumentus (piemēram, rakstus vai tīmekļa lapas), kas saistīti ar lietotāja vaicājumu, un pēc tam izmanto šos dokumentus, lai ģenerētu precīzāku atbildi. Šī metode ir palīdzējusi lielajiem valodu modeļiem (LLM) saglabāt faktisko precizitāti un samazināt halucinācijas, balstot atbildes reālos datos.
Tomēr jaunāki pētījumi atklāj pārsteidzošu atklājumu: AI var sniegt labākas atbildes, ja tam tiek nodrošināts mazāk dokumentu.
Mazāk dokumentu, labākas atbildes
Izraēlas ebreju universitātes pētnieku veiktā studija analizēja, kā dokumentu skaits, ko saņem RAG sistēma, ietekmē tās darbību. Pētījumā kopējais teksta apjoms tika saglabāts nemainīgs – ja tika nodots mazāk dokumentu, tie tika nedaudz paplašināti, lai aizpildītu tādu pašu garumu kā lielāks dokumentu skaits. Tādējādi veiktspējas atšķirības varēja attiecināt tieši uz dokumentu daudzumu, nevis ievades apjomu.
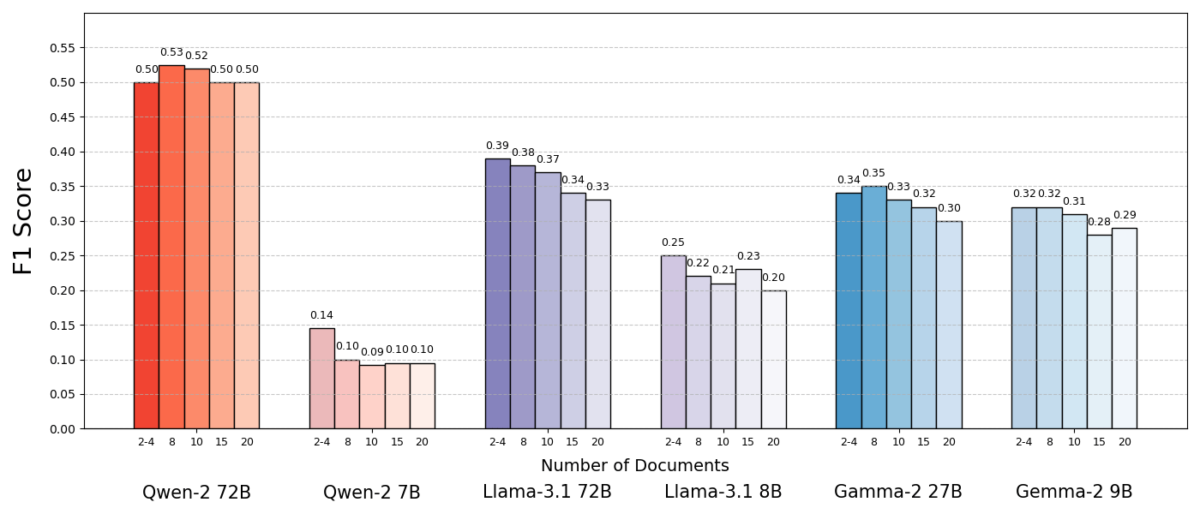
Pētnieki izmantoja jautājumu-atbilžu datu kopu (MuSiQue) ar viktorīnas jautājumiem, kur katrs jautājums sākotnēji tika pārī ar 20 Vikipēdija rindkopām (tikai dažas no tām saturēja atbildi, bet pārējās bija maldinošas). Samazinot dokumentu skaitu no 20 uz tikai 2–4 patiešām atbilstošajiem dokumentiem – un papildinot tos ar nelielu papildu kontekstu, lai saglabātu vienādu garumu – tika izveidoti scenāriji, kuros AI bija jāapstrādā mazāk materiāla, bet kopējais apjoms palika aptuveni tāds pats.
Rezultāti bija pārsteidzoši. Vairumā gadījumu AI modeļi sniedza precīzākas atbildes, kad tiem tika nodots mazāks dokumentu skaits. Veiktspēja uzlabojās ievērojami – dažos gadījumos pat līdz 10% precizitātē (F1 rādītājs), kad sistēma izmantoja tikai dažus atbalstošos dokumentus, nevis lielu kolekciju. Šis paradoksālais uzlabojums tika novērots vairākos atvērtā koda valodu modelos, tostarp Meta Llama variantos, kas norāda, ka šī parādība nav saistīta ar vienu konkrētu AI modeli.
Viens modelis (Qwen-2) bija ievērojams izņēmums, kas spēja apstrādāt vairākus dokumentus bez precizitātes zuduma, bet gandrīz visi pārbaudītie modeļi uzrādīja labākus rezultātus ar mazāku dokumentu skaitu. Citiem vārdiem sakot, papildu atsauces materiālu pievienošāna bieži vien vairāk kaitēja nekā palīdzēja.
Avots: Levy et al.
Kāpēc mazāk var būt vairāk RAG sistēmās?
Šis “mazāk ir vairāk” efekts kļūst saprotams, ja ņem vērā, kā AI valodu modeļi apstrādā informāciju. Ja AI saņem tikai visatbilstošākos dokumentus, konteksts ir fokusēts un bez traucējumiem, līdzīgi kā skolēnam, kuram ir izsniegtas tikai pareizās lappuses mācībām.
Pētījumā modeļi uzrādīja ievērojami labākus rezultātus, kad tiem tika nodoti tikai atbalstošie dokumenti, bez nesaistīta materiāla. Atlikušais konteksts bija ne tikai īsāks, bet arī tīrāks – tas saturēja tikai tos faktus, kas tieši vērsti uz atbildi. Ar mazāk dokumentiem, kurus apstrādāt, modelis varēja pilnībā koncentrēties uz būtisko informāciju, samazinot iespēju apjukt.
Savukārt, kad tika iegūts liels dokumentu skaits, AI bija jāatšķir atbilstošs un nesaistīts saturs. Bieži vien šie papildu dokumenti bija “līdzīgi, bet nesaistīti” – tie varēja dalīt tēmu vai atslēgvārdus ar vaicājumu, bet faktiski nesaturēja atbildi. Šāds saturs var maldināt modeli. AI varēja tērēt pūles, mēģinot savienot punktus starp dokumentiem, kas faktiski neveda pie pareizas atbildes, vai, vēl sliktāk, tā varēja nekorekti apvienot informāciju no vairākiem avotiem. Tas palielina halucināciju risku – situācijas, kad AI ģenerē atbildi, kas izklausās ticama, bet nav balstīta nevienā avotā.
Būtībā, pārāk daudz dokumentu piegāde modelim var atšķaidīt noderīgo informāciju un ieviest pretrunīgus detaļas, padarot grūtāku AI lēmumu par to, kas ir patiess.
Interesanti, ka pētnieki atklāja: ja papildu dokumenti bija acīmredzami nesaistīti (piemēram, nejaušs teksts), modeļi tos labāk ignorēja. Īstās problēmas rada maldinoši dati, kas izskatās atbilstoši: kad visi iegūtie teksti ir par līdzīgām tēmām, AI pieņem, ka tai vajadzētu izmantot visus, un tā var nespēt atšķirt, kuras detaļas patiesībā ir svarīgas. Tas saskan ar pētījuma novērojumu, ka nejauši maldinoši elementi rada mazāku neskaidrību nekā reālistiski maldinoši elementi ievadē. AI var filtrēt acīmredzamas muļķības, bet nedaudz novirzīta informācija ir slazds – tā iekļūst zem atbilstības aizsegā un izkropļo atbildi. Samazinot dokumentu skaitu līdz tikai patiešām nepieciešamajiem, mēs izvairāmies no šo slazdu izveidošanas.
Turklāt ir arī praktiska ieguvums: mazāk dokumentu iegūšana un apstrāde samazina RAG sistēmas skaitļošanas slodzi. Katrs dokuments, kas tiek iegūts, ir jāanalizē (jāiegulda, jāizlasa un jāpievērš uzmanība), kas prasa laiku un skaitļošanas resursus. Lieko dokumentu novēršana padara sistēmu efektīvāku – tā var atrast atbildes ātrāk un ar zemākām izmaksām. Situācijās, kad precizitāte uzlabojās, koncentrējoties uz mazāk avotiem, mēs iegūstam dubultu ieguvumu: labākas atbildes un efektīvāku procesu.

Avots: Levy et al.
RAG pārskatīšana: nākotnes virzieni
Šie pierādījumi, ka kvalitāte bieži vien pārspēj daudzumu informācijas atgūšanā, ir svarīgi nākotnes AI sistēmām, kas paļaujas uz ārējām zināšanām. Tas liek domāt, ka RAG sistēmu dizaineriem vajadzētu prioritizēt gudru dokumentu filtrēšanu un ranžēšanu, nevis tikai daudzumu. Tā vietā, lai iegūtu 100 iespējamos fragmentus un cerētu, ka atbilde ir kaut kur tajos, varētu būt gudrāk iegūt tikai dažus augsti atbilstošus fragmentus.
Pētījuma autori uzsver nepieciešamību pēc atgūšanas metodēm, kas “sasniedz līdzsvaru starp atbilstību un daudzveidību” informācijā, ko tā nodrošina modelim. Citiem vārdiem sakot, mēs vēlamies nodrošināt pietiekamu tematiskā pārklājumu, lai atbildētu uz jautājumu, bet ne tik daudz, ka galvenie fakti tiek noslīcināti nevajadzīga teksta plūsmā.
Nākotnē pētnieki, iespējams, izpētīs metodes, kas palīdzēs AI modeļiem apstrādāt vairākus dokumentus veiksmīgāk. Viena pieeja ir izstrādāt labākas atgūšanas sistēmas vai pārkārtotājus, kas var identificēt, kuri dokumenti patiešām pievieno vērtību un kuri tikai rada pretrunas. Cits virziens ir uzlabot pašus valodu modeļus: ja vienam modelim (piemēram, Qwen-2) izdevās tikt galā ar daudziem dokumentiem bez precizitātes zuduma, tā apmācības vai struktūras izpēte varētu sniegt pavedienu, kā padarīt citus modeļus izturīgākus. Varbūt nākotnes lielie valodu modeļi iekļaus mehānismus, lai atpazītu, kad divi avoti saka to pašu (vai pretrunā viens otram), un attiecīgi koncentrētos. Mērķis būtu ļaut modeļiem izmantot daudzveidīgus avotus, neiekrītot neskaidrībās – efektīvi gūstot labāko no abām pusēm (informācijas plašums un fokusa skaidrība).
Ir arī vērts atzīmēt, ka, tā kā AI sistēmas iegūst lielākus konteksta logus (spēju vienlaikus lasīt vairāk teksta), vienkārši vairāk datu ievietošana uzdevumā nav universāls risinājums. Lielāks konteksts neautomātiski nozīmē labāku izpratni. Šis pētījums parāda, ka pat ja AI tehniski var izlasīt 50 lappuses vienā reizē, tai nododot 50 jauktas kvalitātes informācijas lapas var neradīt labu rezultātu. Modelis joprojām gūst labumu no kārtota, atbilstoša satura, nevis nejaušas datu kaudzes. Patiesībā, gudra informācijas atgūšana var kļūt vēl svarīgāka milzīgu konteksta logu laikmetā – lai nodrošinātu, ka papildu ietilpība tiek izmantota vērtīgām zināšanām, nevis troksnim.
Atklājumi no pētījuma “Vairāk dokumentu, tāds pats garums” mudina pārskatīt mūsu pieņēmumus AI pētniecībā. Dažreiz visu pieejamo datu piegāde AI nav tik efektīva, kā mēs domājam. Koncentrējoties uz visatbilstošākajām informācijas daļām, mēs ne tikai uzlabojam AI ģenerēto atbilžu precizitāti, bet arī padarām sistēmas efektīvākas un uzticamākas. Tas ir pretintuitīvs mācību stundas, bet ar aizraujošām sekām: nākotnes RAG sistēmas varētu būt gan gudrākas, gan vieglākas, rūpīgi izvēloties mazāk, bet labākus dokumentus, ko iegūt.
https://www.unite.ai/